ずっとSELECT INSERTが便利で使ってた
SELECT INSERT(構文的に正しくは INSERT SELECT だけど勝手に SELECT INSERTと呼んでる…?)を使うのをやめて、代わりに Auroraに搭載されている機能を使った話。
所属会社の担当プロダクトの本番環境でこのAuroraを使ってるのですが、運用してデータが蓄積されていくにつれていくつか問題点が出てきました。
Amazon Aurora MySQL
https://aws.amazon.com/jp/rds/aurora/
RDBで、要は MySQL を AWS に最適化して機能を増やしたSaaS。
クエリとかは MySQLで使えるクエリが使える(厳密に使えないのいくつかあるかも)
SELECT INSERT で長時間ロックが掛かってしまう
インフラ・負荷周りの前提情報
- バージョン: AWS Aurora mysql 5.6(の現時点での最新)
- クラスタ: writer 1台、reader 1台(オートスケール)
- インスタンスサイズ: r5.16xlarge
ユーザー任意のタイミングで CREATE TABLE の後に SELECT INSERT する機能(要はレコード絞ってテーブルコピー)があるのですが、この出力結果のテーブルが次のようになっています。
- 1テーブル 平均 0.8GB
- 最小100MB、 最大40GB / 1テーブル
- 約1000テーブル以上/日 でコピー
-- イメージこんな感じ
CREATE TABLE public_report ...;
INSERT INTO public_report -- 作りたいテーブル
SELECT * FROM report r -- 元データのあるテーブル
INNER JOIN report_setting rs -- 公開情報のあるテーブル
ON r.PRIMARY_KEY = rs.PRIMARY_KEY
AND rs.is_display = TRUE -- 公開設定されてる情報だけに絞る
;
このSQL実行後のコピー完了したテーブルのサイズがすごく大きい。
report(元テーブル) → SELECT INSERT → public_report(コピーテーブル)
^これは最大80GBくらいある ^これが 最大40GBくらいある
大体の SELECT INSERT は高速なのですが、極端にサイズの大きないくつかのテーブルで非常に時間がかかってしまっている状態でした(ファイルサイズに比例して書き込みに時間がかかるので重い)
調べてみると、SELECT INSERT するとロックがかかる事が公式マニュアルに乗っていました。 https://dev.mysql.com/doc/refman/5.6/ja/insert-select.html
ソフトウェア的な挙動の前提
上記の通り、SELECT INSERT するとロックがかかり書き込みができなくなります。 ですが、僕が担当するプロダクトでは ETL処理による出力の書き込みが report(元テーブル)に対して 30分に1回行われます。
つまり、 SELECT INSERT の最中に ETL処理出力の書き込みが重なると、 40GBのINSERT処理を待つ必要があります。
この事象が起こってた時は、 show full processlist; でプロセス確認すると、5000秒以上掛かってる SELECT INSERT が稀に見られました。
- 5000秒以上掛かるクエリはプロダクトとして許容できない
- ETL処理も大幅に遅延してしまうため挙動を変えず(現在の仕様のまま)に競合しないやり方に変える必要が出てきた
これの課題に対する単純な解決方法
解決方法は単純で、 SELECT INSET を辞めて、Auroraでのみ使えるクエリで解決しました。
SELECT INTO OUTFILE S3で CSV形式でS3へファイル出力LOAD DATA FROM S3で 出力した CSVからデータをインサート
変更前後は次の図のようになります。
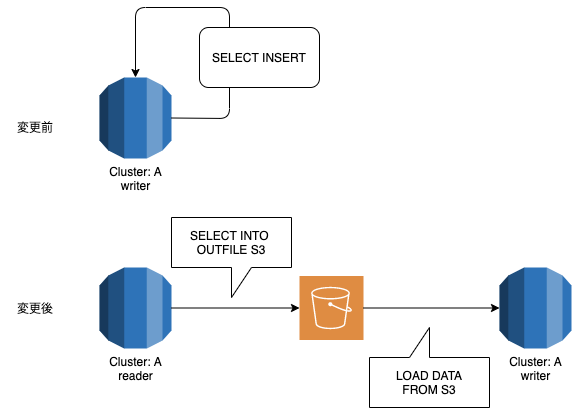
ざっくり説明するとこう
- 変更前: writerだけで完結するがロックが掛かる
- 変更後: writerとreaderにクエリを流すが、ロックが掛からない
INTO OUTFILE S3, LOAD DATA FROM S3 って何
INTO OUTFILE と LOAD DATA はそれぞれ MySQLにも実装されているクエリです。が、S3 出力に対応してるのは Auroraだけであり、Aurora独自の実装です。
SELECT INTO構文
こんな感じで、SELECTした結果を直接S3に出力できる。
SELECT * FROM report r
INNER JOIN report_setting rs
ON r.PRIMARY_KEY = rs.PRIMARY_KEY
AND rs.is_display = TRUE
INTO OUTFILE S3 's3://#BUCKET/tmp/#HASH'
FIELDS TERMINATED BY ',';
FROM S3 で S3に存在するファイルをテーブルに読み込む事ができる。
LOAD DATA FROM S3 PREFIX 's3://#BUCKET/tmp/#HASH'
REPLACE INTO TABLE public_report
FIELDS TERMINATED BY ','
(/* テーブルのカラム全て指定 */)
実施前後でのマトリクス
| 項目 | SELECT INSERT |
INTO OUTFILE S3 → LOAD DATA FROM S3 |
|---|---|---|
| 実行あたりの単純速度 | 速い | 遅い |
| テーブルロック | 有り | 無し |
| オートスケール対応 | してない | してる(INTO OUTFILEはスケール可) |
| 最終的なパフォーマンス | - | UP |
実行あたりの単純速度は、1回あたりの実行時間は長くなった事を指します。
やはり SELECT INSERT は高速で、書き込みが競合せず即座に完了するのであれば SELECT INSERT が速いし一番良い。
僕の担当プロダクト的には合わなかったという話なのでケースバイケース。
このチューニングを行ってみての感想
僕の担当プロダクトでは、ETL処理からの書き込みがあるため、下記を徹底すべきなのかなと感じた。
- 書き込み処理は writerエンドポイント
- 読み込み処理は readerエンドポイント
今現時点で writerに対して SELECTしてるクエリがいくつかあるので、洗い出してクエリ実行の向き先を変える必要がありそう。
年1更新でしたが今年2ポスト目です。これからもチマチマ更新したいと思います。